
В настоящее время в разработке ПО достаточно часто применяется многоуровневая архитектура или многослойная архитектура (n-tier architecture), в рамках которой компоненты проекта разделяются на уровни (или слои). Классическое приложение с многоуровневой архитектурой, чаще всего, состоит из 3 или 4 уровней, хотя их может быть и больше, учитывая возможность разделения некоторых уровней на подуровни. Одним из примеров многоуровневой архитектуры является предметно-ориентированное проектирование (Domain-driven Design, DDD), где основное внимание сконцентрировано на предметном уровне.
В проектах с многоуровневой архитектурой можно выделить четыре уровня (или слоя):
- Слой представления, с которым взаимодействует пользователь или клиентский сервис. Реализацией слоя представления может быть, например, графический пользовательский интерфейс или веб-страница.
- Сервисный слой, реализующий взаимодействие между слоями представления и бизнес-логики. Примерами реализаций сервисного слоя являются контроллеры, веб-сервисы и слушатели очередей сообщений.
- Слой бизнес-логики, в котором реализуется основная логика проекта. Компоненты, реализующие бизнес-логику, обрабатывают запросы, поступающие от компонентов сервисного слоя, а так же используют компоненты слоя доступа к данным для обращения к источникам данных.
- Слой доступа к данным — набор компонентов для доступа к хранимым данным. В качестве источников данных могут выступать различного рода базы данных, SOAP и REST-сервисы, файлы на файловой системе и т.д.
Направление зависимостей между слоями идёт от слоя представления к слою доступа к данным. В идеальной ситуации каждый слой зависит только от следующего слоя: слой представления зависит от сервисного слоя (например, представление зависит от контроллера), сервисный слой зависит от слоя бизнес-логики (например, контроллер зависит от бизнес-сервиса), а слой бизнес-логики — от слоя доступа к данным (например, бизнес-сервис зависит от репозитория). При этом компоненты бизнес-слоя могут зависеть от других компонентов бизнес-слоя, тогда как в других слоях аналогичные зависимости нежелательны (например, зависимость одного репозитория от другого). Так же нежелательны зависимости в обратном направлении (бизнес-слой не должен зависеть от сервисного слоя) и зависимости между слоями, не являющимися соседними (сервисный слой не должен зависеть от слоя доступа к данным, например).
На практике иногда приходится сталкиваться с примерами, когда бизнес-логика частично или полностью находится в контроллере, а иногда встречаются и вовсе случаи обращения компонентов слоя представления к слою доступа к данным. Несоблюдение разделения кода между слоями непременно приводит к путанице, замедляет процесс разработки и развития проекта и делает процесс поддержки проекта трудоёмким и дорогим.
Допустим, у нас есть код, реализующий бизнес-логику приложения, который находится в контроллере. Что если нам требуется разработать SOAP-сервис, реализующий ту же функциональность? Мы можем скопировать существующий код в SOAP-сервис и внести в него изменения по мере необходимости. Будет ли ли такой подход работать? Да! Вызовет ли такой подход проблемы? Тоже да! В процессе жизненного цикла проекта требования к нему имеют свойство меняться, что ведёт к неизбежным изменениям и в коде. Но при таком подходе нам придётся изменить код и в контроллере, и в SOAP-сервисе, а также внести изменения в их тесты (вы же тестируете свой код?). Но граздо правильнее будет вынести общий код, реализующий бизнес-логику, в компонент слоя бизнес-логики. В этом случае в контроллере и SOAP-сервисе останется код, преобразующий запрос к общему виду, понятному компоненту бизнес-логики.
Очевидным фактом является то, что бизнес-логика — самая важная составляющая вашего проекта. И именно с проработки компонентов слоя бизнес-логики должна начинаться разработка проекта.
К слову сказать, очень хорошей практикой является применение UML, в данном конкретном случае — диаграммы классов. Из собственной практики помню случай, когда я решил для почти готового проекта составить диаграмму классов, результатом чего стал рефакторинг, уменьшивший количество кода примерно на 20%. Составление диаграммы классов на ранних этапах разработки позволяет уменьшить дублирование кода, сделать структуру классов и зависимости между ними более понятными.
В так полюбившейся мне книге Роберта Марина «Чистая архитектура» автор пропагандирует идею независимости (или минимизации зависимости) архитектуры приложения от внешних факторов: фреймворков, баз данных и прочих сторонних зависимостей. Это говорит не об отказе от использования этих зависимостей (вы же не будете разрабатывать собственный механизм трансляции HTTP-вызовов или хранения данных?), а о минимизации их влияния на архитектуру вашего проекта.
Разработка бизнес-логики
Давайте возьмём в качестве примера разработку блокнота, который пользователь может использовать для работы с заметками. Заметьте, я не указал, что это будет онлайн-сервис или настольное приложение. Для начала определимся с набором типов (классов и интерфейсов), которые нам понадобятся для нашего проекта. Класс-сущность, описывающий заметку — Note, компонент бизнес-логики, реализующий работу с заметками — NoteService, ещё нам потребуется компонент слоя доступа к данным — NoteRepository. Простая реализация NoteService — SimpleNoteService, использует NoteRepository для доступа к источнику данных. Диаграмма классов, описывающая текущую архитектуру, будет достаточно простая:
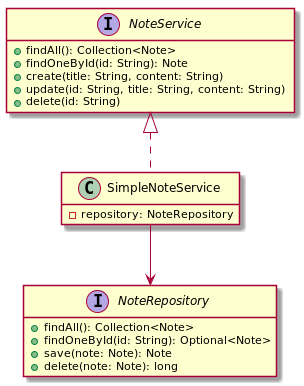
Теперь можно описать эти типы в коде, написать тесты для SimpleNoteService и реализовать этот класс.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
package name.alexkosarev.notepad.note; import java.util.Date; public class Note { private String id; private String title; private String content; private Date dateCreated; private Date dateModified; private String userAccountId; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
package name.alexkosarev.notepad.note; import java.util.Collection; public interface NoteService { Collection<Note> findAll(); Note findOneById(String id); void create(String title, String content); void update(String id, String title, String content); void delete(String id); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
package name.alexkosarev.notepad.note; import java.util.Collection; import java.util.Optional; interface NoteRepository { Collection<Note> findAll(); Optional<Note> findOneById(String id); Note save(Note note); long delete(Note note); } |
Область видимости типа NoteRepository преднамеренно ограничена пакетом, чтобы никакие другие компоненты, кроме реализаций NoteService, не могли его использовать. Для тестов SimpleNoteService нам потребуются JUnit с Mockito:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 |
package name.alexkosarev.notepad.note; import name.alexkosarev.notepad.exceptions.EntityNotFoundException; import org.junit.Assert; import org.junit.Rule; import org.junit.Test; import org.junit.rules.ExpectedException; import org.mockito.ArgumentMatchers; import org.mockito.Mockito; import java.util.Collection; import java.util.Objects; import java.util.Optional; import java.util.UUID; import java.util.stream.Collectors; import java.util.stream.IntStream; public class SimpleNoteServiceTest { @Rule public ExpectedException expectedException = ExpectedException.none(); private NoteRepository repository = Mockito.mock(NoteRepository.class); private SimpleNoteService noteService = Mockito.spy(new SimpleNoteService(this.repository)); @Test public void findAll_ReturnsCollection() { Mockito.doReturn(IntStream.range(0, 3).mapToObj(i -> new Note()).collect(Collectors.toList())) .when(this.repository).findAll(); Collection<Note> collection = this.noteService.findAll(); Mockito.verify(this.repository).findAll(); Assert.assertNotNull(collection); Assert.assertEquals(3L, collection.size()); } @Test public void findOneById_NoteExists_ReturnsNote() { String id = UUID.randomUUID().toString(); Mockito.doReturn(Optional.of(new Note())) .when(this.repository).findOneById(ArgumentMatchers.any()); Note note = this.noteService.findOneById(id); Mockito.verify(this.repository).findOneById(ArgumentMatchers.eq(id)); Assert.assertNotNull(note); } @Test public void findOneById_NoteDoesNotExist_ThrowsException() { this.expectedException.expect(EntityNotFoundException.class); String id = UUID.randomUUID().toString(); Mockito.doReturn(Optional.empty()) .when(this.repository).findOneById(ArgumentMatchers.any()); try { this.noteService.findOneById(id); } catch (EntityNotFoundException e) { Mockito.verify(this.repository).findOneById(ArgumentMatchers.eq(id)); Assert.assertEquals(id, e.getId()); throw e; } } @Test public void create_ReturnsVoid() { String title = "new note"; String content = "new note content"; this.noteService.create(title, content); Mockito.verify(this.repository).save(ArgumentMatchers.argThat(note -> Objects.nonNull(note.getId()) && Objects.nonNull(note.getDateCreated()) && Objects.equals(title, note.getTitle()) && Objects.equals(content, note.getContent()))); } @Test public void update_NoteExists_ReturnsVoid() { String id = UUID.randomUUID().toString(); String title = "new note"; String content = "new note content"; Mockito.doReturn(Note.builder().id(id).build()).when(this.noteService) .findOneById(ArgumentMatchers.any()); this.noteService.update(id, title, content); Mockito.verify(this.noteService).findOneById(ArgumentMatchers.eq(id)); Mockito.verify(this.repository).save(ArgumentMatchers.argThat(note -> Objects.equals(id, note.getId()) && Objects.nonNull(note.getDateModified()) && Objects.equals(title, note.getTitle()) && Objects.equals(content, note.getContent()))); } @Test public void update_NoteDoesNotExist_ThrowsException() { this.expectedException.expect(EntityNotFoundException.class); String id = UUID.randomUUID().toString(); String title = "new note"; String content = "new note content"; Mockito.doThrow(new EntityNotFoundException(id)).when(this.noteService) .findOneById(ArgumentMatchers.any()); try { this.noteService.update(id, title, content); } catch (EntityNotFoundException e) { Mockito.verify(this.noteService).findOneById(ArgumentMatchers.eq(id)); Mockito.verify(this.repository, Mockito.never()).save(ArgumentMatchers.any()); Assert.assertEquals(id, e.getId()); throw e; } } @Test public void delete_NoteExists_ReturnsVoid() { String id = UUID.randomUUID().toString(); Mockito.doReturn(Note.builder().id(id).build()).when(this.noteService) .findOneById(ArgumentMatchers.any()); Mockito.doReturn(1L).when(this.repository).delete(ArgumentMatchers.any()); this.noteService.delete(id); Mockito.verify(this.noteService).findOneById(ArgumentMatchers.eq(id)); Mockito.verify(this.repository).delete(ArgumentMatchers.argThat(note -> Objects.equals(id, note.getId()))); } @Test public void delete_NoteDoesNotExist_ReturnsVoid() { this.expectedException.expect(EntityNotFoundException.class); String id = UUID.randomUUID().toString(); Mockito.doThrow(new EntityNotFoundException(id)).when(this.noteService) .findOneById(ArgumentMatchers.any()); try { this.noteService.delete(id); } catch (EntityNotFoundException e) { Mockito.verify(this.noteService).findOneById(ArgumentMatchers.eq(id)); Mockito.verify(this.repository, Mockito.never()).save(ArgumentMatchers.any()); Assert.assertEquals(id, e.getId()); throw e; } } } |
Реализация SimpleNoteService:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
package name.alexkosarev.notepad.note; import name.alexkosarev.notepad.exceptions.EntityNotFoundException; import java.util.Collection; import java.util.Date; import java.util.UUID; public class SimpleNoteService implements NoteService { private final NoteRepository repository; @Override public Collection<Note> findAll() { return this.repository.findAll(); } @Override public Note findOneById(String id) { return this.repository.findOneById(id) .orElseThrow(() -> new EntityNotFoundException(id)); } @Override public void create(String title, String content) { this.repository.save(Note.builder().id(UUID.randomUUID().toString()) .title(title).content(content).dateCreated(new Date()).build()); } @Override public void update(String id, String title, String content) { Note note = this.findOneById(id); note.setTitle(title); note.setContent(content); note.setDateModified(new Date()); repository.save(note); } @Override public void delete(String id) { this.repository.delete(this.findOneById(id)); } } |
Класс SimpleNoteService объявлен финальным, что соответствует принципу открытости/закрытости (OCP). Обратите внимание, что метод findOneById в SimpleNoteService выкидывает исключение EntityNotFoundException, если получает от репозитория пустой ответ. Вы можете возвращать null или пустой экземпляр Optional или даже выкидывать проверяемое исключение, вариант поведения в данном случае не имеет особого значения, важно, как вам удобнее будет обрабатывать исключительные ситуации.
В результате у нас получился компонент, реализующий бизнес-логику работы с заметками, не имеющий зависимостей от сторонних библиотек. В следующих статьях я продолжу описывать применение многоуровневой архитектуры, а также буду рассматривать применение различных фреймворков в компонентах проекта с многоуровневой архитектурой.